D.A.D. — Driver's Assistant with Detection
Implementing YOLOv1 from scratch in PyTorch as a lightweight blind-spot monitor for visually impaired drivers.
Project overview. This post details the development of Driver’s Assistant with Detection (D.A.D.), a computer vision system designed to reduce blind-spot accidents caused by visual impairment. We walk through the process of implementing the YOLOv1 architecture from scratch using OOP principles to create a lightweight, efficient detection model.
Introduction
According to the National Highway Transportation Safety Administration (NHTSA), 94% of all car accidents are related to human error. A significant portion of these incidents involves the nearly 20 million U.S. citizens living with visual impairments. The most dangerous scenarios for these drivers often involve blind spots — areas where vehicles like buses, bikes, motorbikes, or other cars disappear from view.
This project mitigates that risk by developing a detection system that alerts drivers to surrounding vehicles. By leveraging the speed of the You Only Look Once (YOLO) algorithm, we created a model capable of real-time inference on resource-constrained devices.
Methodology
1. The algorithm: YOLOv1 from scratch
Unlike multi-stage detectors that use region proposal networks, YOLO frames object detection as a single regression problem. We implemented YOLOv1 from scratch to ensure a deep understanding of the architecture and to optimize it for our specific use case.
The model divides an input image into an \(S \times S\) grid. If the center of an object falls into a grid cell, that cell is responsible for detecting it. The network predicts bounding boxes \(B\), confidence scores, and class probabilities simultaneously.
The loss function used is the sum of squared error (SSE):
\[Loss = \sum_{i=0}^{S^2} \text{CoordError} + \text{IoUError} + \text{ClassError}\]We rigorously handled the encoding and decoding of bounding boxes to map predictions from the \(7 \times 7\) grid format back to the \(XYXY\) format required for visualization.
2. Lightweight architecture
Efficiency was a primary goal. While standard detection models are often massive, our custom implementation focuses on minimizing parameter count without sacrificing utility.
- Total parameters: 1.3 million
- Storage cost (FP32): ~5.2 MB
- Storage cost (INT8): ~1.3 MB
This compact size makes D.A.D. highly suitable for embedded devices used in automotive settings.
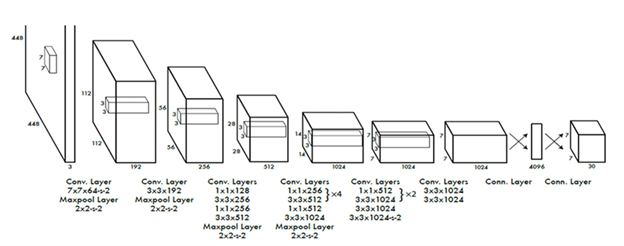
Figure 1: The custom YOLO architecture designed for the project.
3. Object-oriented design
To ensure scalability and maintainability, the project relies heavily on OOP principles. The codebase is modularized into distinct responsibilities:
-
dataset.py— handles complex data loading, combining VOC2007 and VOC2012, and parsing XML annotations. -
model.py— defines the network structure usingConvUnitandYoYoclasses. -
loss.py— implements the custom SSE loss function with vectorized masking to replace slow loops. -
utils.py— Non-Max Suppression (NMS) and Mean Average Precision (mAP) helpers.
Experimental setup
- Dataset: PascalVOC (combined 2007 train/val/test + 2012 train/val).
- Classes: filtered for relevant road objects: Bicycle, Bus, Car, Motorbike.
- Input resolution: \(224 \times 224\).
- Metric: Mean Average Precision (mAP@50).
Results
Training convergence
We trained the model for 300 epochs. The loss curves demonstrate that the model successfully converged.
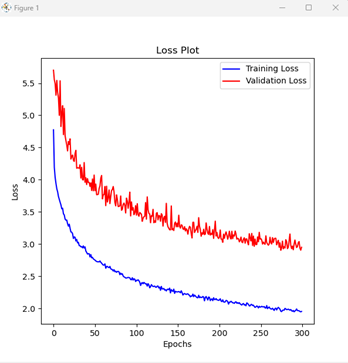
Figure 2: Training vs. validation loss over 300 epochs.
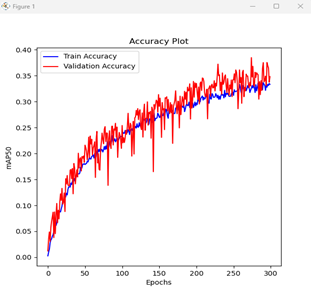
Figure 3: Mean Average Precision (mAP) increasing over time.
Inference capabilities
Static inference: the model successfully detects and classifies vehicles in standalone images with high confidence scores. The NMS implementation effectively removes duplicate boxes.

Figure 4: Single-image inference on Bus, Car, Motorbike, and Bicycle.
Live inference: we connected the model to a live webcam feed to simulate a driver’s perspective. While we encountered an OpenCV display bug that prevented bounding boxes from rendering on the live stream, the CLI successfully output correct class predictions and confidence scores in real time.
Conclusion
D.A.D. demonstrates that a lightweight, OOP-based implementation of YOLOv1 can perform effective vehicle detection with only 1.3 million parameters, balancing accuracy with the efficiency required for real-world driving assistants.
Future work will focus on:
- Resolving the OpenCV live-rendering bug.
- Expanding the dataset to improve robustness in diverse lighting conditions.
- Further quantizing the model to reduce size for edge deployment.