1-Lipschitz Layers Beyond Classification
Exploring 1-Lipschitz layers for robust object detection on SVHN with a Tinier SSD architecture.
Project overview. This work explores the experimental application of 1-Lipschitz layers — typically used to certify robustness in classification tasks — to the more complex domain of object detection. We analyze the trade-offs between robustness, expressiveness, and accuracy using the SVHN dataset on a custom Tinier SSD architecture.
Introduction
Deep learning models are notoriously vulnerable to adversarial attacks, where imperceptible perturbations in input data can cause drastic failures in prediction. While research has successfully leveraged Lipschitz continuous functions to bound model behavior and guarantee robustness in classification tasks, this approach remains largely unexplored for object detection.
Object detection presents a unique challenge: unlike classification, which assigns a single label to an image, detection involves both regression (bounding boxes) and classification (labels) simultaneously.
This project implements SDP-based 1-Lipschitz layers within a Tinier SSD macro-architecture to test if we can bound the model’s global Lipschitz constant and certify robustness against L2-based Projected Gradient Descent (PGD) attacks.
Methodology
1. The theory: Lipschitz continuity
A function \(f: \mathbb{R}^n \to \mathbb{R}^m\) is Lipschitz continuous if it satisfies:
\[\|f(x) - f(y)\| \le L \|x - y\| \quad \forall x, y \in \mathbb{R}^n\]Here, \(L\) is the Lipschitz constant, representing the upper bound of the output change relative to the input change. By constraining \(L=1\) (1-Lipschitz), we can theoretically guarantee that small input perturbations result in bounded output changes, ensuring stability.
2. The architecture: Tinier SSD
We adopted the Tinier SSD architecture, a lightweight version of the Single Shot Detector. To integrate robustness, we replaced standard convolutional layers with SDP-based Lipschitz layers.
A core challenge arose: 1-Lipschitz layers often require input and output channels to match, which conflicts with the expanding and contracting feature maps of a detection backbone. To remedy this, we used Normalized Convolutional Layers at the very start (to expand channels) and very end (to match prior boxes) of the network.
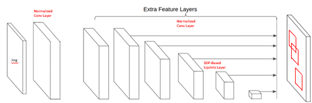
Figure 1: Tinier SSD architecture integrating Lipschitz layers with normalized entry/exit layers.
3. Layer configurations
We compared three configurations to analyze the trade-off between strict mathematical robustness and practical performance:
- Spectral-norm-based layers — fully 1-Lipschitz (most restrictive).
- Standard convolutional layers — unbounded (control / high expressiveness).
- L2-normalized layers — weights normalized by L2 norm (experimental balance).
Experimental setup
- Dataset: Street View House Numbers (SVHN), chosen for its simplicity relative to COCO/PascalVOC given the high training cost of Lipschitz models.
- Attack: custom L2-based PGD attack with \(\epsilon = 0.5\).
- Hardware: RTX 4090.
Results
Accuracy and robustness trade-off
| Configuration | Clean mAP (%) | Adversarial mAP (%) | Observations |
|---|---|---|---|
| Naïve (Baseline) | 78.79 | 42.07 | High accuracy, but severe drop under attack. |
| Spectral-norm | 0.00 | 0.00 | Infeasible. Constraints too restrictive. |
| Standard Conv | 78.67 | 58.60 | High expressiveness, generated many false positives. |
| L2-normalized | 61.75 | 52.63 | Lowest accuracy drop, most consistent predictions. |

Figure 2: Naïve model — clean (left) vs. adversarial (right).

Figure 3: L2-normalized model — clean (left) vs. adversarial (right).
Lipschitz constant analysis
We analyzed the Lipschitz constant across layers for the “Standard Conv” configuration. The global Lipschitz constant reached ~95, driven largely by the unbounded first and last layers. Interestingly, the constant increases as the network gets deeper, particularly in the classification heads.

Figure 4: Analysis of Lipschitz constants across network layers.
Key findings
- The “fully 1-Lipschitz” barrier. Implementing a fully 1-Lipschitz network (via spectral norm) for object detection is currently impractical. The constraints destroy the expressiveness required for regression and classification simultaneously.
- Consistency vs. accuracy. While L2-normalized layers did not achieve the highest mAP, they offered the best stability — the gap between clean and attacked mAP was the smallest.
- Parameter efficiency. A 7M-parameter partially-bounded Lipschitz model was outperformed by a 338k-parameter naïve model on clean data, suggesting that scale alone cannot compensate for the restrictiveness of Lipschitz bounds without new architectural innovations.
Conclusion
This work establishes a baseline for applying Lipschitz continuity to object detection. While fully certifying robustness remains a challenge due to expressiveness constraints, L2-normalization offers a promising path for reducing false positives and stabilizing predictions against adversarial attacks. Future work should explore layers that are “mostly” 1-Lipschitz or investigate these constraints on segmentation tasks, where pixel-based attacks are most prevalent.