ADMM Pruning for Efficient Deep Learning
Comparing ADMM-based optimization pruning against magnitude-based heuristics on lightweight CIFAR-10 models.
Project overview. This post explores the implementation of the Alternating Direction Method of Multipliers (ADMM) for pruning lightweight Deep Neural Networks. We compare this optimization-based approach against traditional magnitude-based pruning on the CIFAR-10 dataset.
Introduction
Deep neural networks have achieved remarkable performance across various domains, but their high computational and memory costs often hinder deployment on resource-constrained devices. Weight pruning has emerged as an effective strategy to reduce model complexity while preserving performance.
This project implements ADMM-based pruning on lightweight architectures (MobileNetV2, MobileNetV3) and compares it against a magnitude-based baseline. While heuristic methods are simple and effective, ADMM offers a principled mathematical framework for enforcing sparsity.
Methodology
1. Heuristic — magnitude-based pruning
Magnitude pruning assumes that weights with the smallest absolute values contribute the least. The objective is to minimize the loss function \(f(W)\) subject to a cardinality constraint:
\[\min f(W) \quad \text{s.t.} \quad \text{card}(W) \le l\]where \(l\) is the target number of non-zero weights. This method enforces hard constraints by simply pruning weights after every step.
2. Optimization — ADMM-based pruning
ADMM formulates pruning as a constrained optimization problem. We introduce an auxiliary variable \(Z\) and an indicator function \(g(Z)\) that enforces the sparsity set \(S\):
\[\min_{W} f(W) + g(Z) \quad \text{s.t.} \quad W = Z\]Solved using the Augmented Lagrangian:
\[L_{p}(W,Z,U) = f(W) + g(Z) + \frac{\rho}{2} \|W - Z + U\|_F^2\]where \(U\) are the dual variables and \(\|\cdot\|_F\) is the Frobenius norm. The algorithm iteratively updates \(W\), \(Z\) and \(U\), where \(Z\) is projected onto the sparsity set \(S\) via Euclidean projection.
Experimental setup
We validated experiments using CIFAR-10 on three modern lightweight architectures:
- MobileNetV2
- MobileNetV3-Small
- MobileNetV3-Large
Settings:
- Pruning ratio: uniform \(s = 0.5\) across all layers.
- Optimization: \(\rho = 0.01\), Adam optimizer, lr = 0.001.
Results
Training convergence
ADMM exhibited higher training loss and slower convergence compared to the baseline, indicating the difficulty of optimization under strict sparsity constraints.
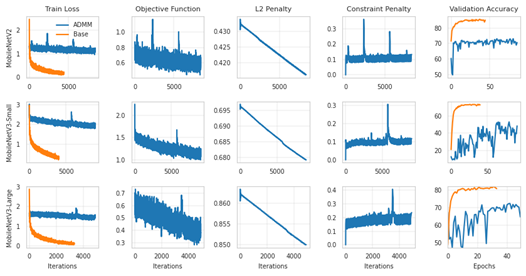
Figure 1: Training objective and validation accuracy.
Accuracy comparison
| Model | Method | Pre-pruning Acc (%) | Post-pruning Acc (%) |
|---|---|---|---|
| MobileNetV2 | Base | 10.00 | 70.60 |
| ADMM | 80.66 | 67.10 | |
| MobileNetV3-Small | Base | 48.33 | 64.57 |
| ADMM | 72.47 | 68.48 | |
| MobileNetV3-Large | Base | 35.97 | 35.97 |
| ADMM | 85.06 | 60.13 |
For MobileNetV2 the baseline substantially outperformed ADMM, suggesting that larger model size amplified the optimization challenge.
Weight distributions
- Baseline — approximately normal distribution; pruning removes weights near zero.
- ADMM — many weights are driven exactly to zero during optimization. After pruning, the distribution becomes multimodal, suggesting a sharper separation between important and unimportant weights.
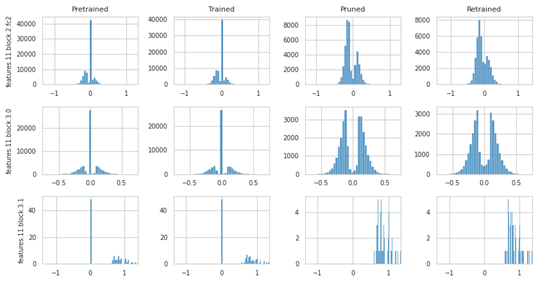
Figure 2: Weight distribution of ADMM method showing multimodal separation.
Key findings
- Structured sparsity — ADMM can induce sharper sparsity patterns and potentially better accuracy on specific architectures.
- Optimization difficulty — ADMM introduces significant stability challenges, characterized by slower convergence and lower pre-pruning accuracy.
- Complexity sensitivity — the method struggled with the larger MobileNetV2, indicating it may need improved optimization strategies for more complex architectures.
ADMM is a principled framework, but it is not yet reliably effective for all lightweight architectures compared to a simple magnitude-based baseline.